



Machines that can emulate human intelligence have captured our imagination for a long time. Originally, they were a product of science fiction, but now intelligent machines are a ubiquitous part of our daily lives, both personally and professionally. In our personal lives, we interact with our phones using voice commands like “Hey Siri” or “Hey Google” to play music or search for nearby restaurants. In professional settings, intelligent machines are utilized by doctors to enhance the accuracy of disease diagnosis, by retailers to boost sales, and by manufacturers to automate shop floor operations. These are only a few examples of how intelligent machines can be utilized across various market verticals such as energy, banking, insurance, and hospitality.
Machine learning is the technology behind intelligent machines. It is a branch of computer science that involves simulating intelligent behavior in computers similar to humans. According to Fortune Business Insights, a market research firm, the global machine learning market is expected to grow from $21.17 billion in 2022 to $209.91 billion in 2029.
Supervised and unsupervised learning are the two prominent machine learning techniques used to train machines to become intelligent. Both methods are employed to solve different business problems; however, each excels in its specific areas. Nevertheless, both methods come with their own set of advantages and challenges.
Read more: Revolutionizing NLP: 10 Cutting-Edge Applications of Deep Learning
Supervised Learning
Supervised learning is a machine learning technique that involves training machines under supervision, typically with the help of a data scientist. This approach is similar to a student learning from a teacher. To train a machine using supervised learning, a data scientist creates a labeled database, where data is tagged with labels that represent specific objects. In other words, the input data is already mapped to the output data.

For instance, if a machine trained on the data labeled for a triangle is fed with the above image, it will identify the image as a triangle.
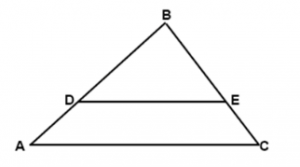
Similarly, if the above image is fed to the machine, it will identify the two triangles present in the figure.
Such a capability helps solve the classification computing problem.
The problem involves classifying a set of objects into subsets based on their features. One way to train a machine for this task is by using labeled databases that represent different objects.
Take a look at the second figure. If the machine is trained on the data labeled for a trapezium as well, it will be able to identify not only two triangles but also one trapezium. In the real world, this capability can be useful in scenarios such as segregating emails into the inbox or spam folder, extracting specific data from a dataset, text recognition for translation, and more.
The image below provides a better understanding of this process, where circles are separated from triangles.
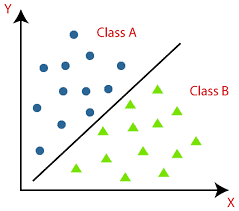
Supervised learning is not only helpful in classifying objects but also for solving regression computing problems. Such problems involve understanding the relationship between independent and dependent variables, specifically how the output data changes with the change in the input data. For instance, an increase in temperature can lead to a reduction in humidity. This technique is applicable in various real-world scenarios, including weather predictions, stock price changes, sales figures variations during different seasons, and more.
The image below shows the relationship between sales calls and deals closed for a better understanding. 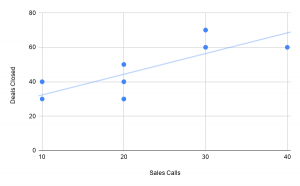
Unsupervised Learning
Unsupervised learning is a machine learning technique that involves training machines with an unlabeled database. It is akin to students learning on their own without the guidance of a teacher.
However, the machine is designed to group data based on similarities, patterns, and differences, thus only capable of identifying the structure and pattern from the input data.
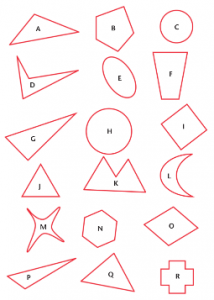
If the above figure is fed to the machine trained with unsupervised learning, it will segregate circles, triangles, pentagons, and other structures into separate clusters.
Such a capability of unsupervised learning helps solve clustering computing problems. The process of dividing objects into clusters based on their similarities and differences is known as clustering. In the real world, clustering can be used to group customers by their purchasing behavior for targeted marketing, aggregate similar queries on the FAQ page, identify accident-prone zones to prevent accidents, and more.
Unsupervised learning, as it also discovers a pattern in the given cluster of objects, helps solve the association computing problem as well. It involves discovering the probability of the co-occurrences of objects in a collection. In the real world, the association can be useful to cross-sell a product to the customer based on their buying history, optimize the inventory as per customer demands, deliver better care to the patients in a population health drive, and more.
As we already know supervised and unsupervised machine learning techniques to train machines, let’s explore the differences between the two.
| Supervised Learning | Unsupervised Learning |
| Uses labeled input/output data | Uses only unlabeled input data |
| Highly accurate and trustworthy results | Higher risk of inaccurate results |
| Can be trained iteratively to increase the accuracy of the output | Requires human intervention to validate the output |
| Unusable to crunch big data, as data labeling gets complicated | The preferred technique to process big data |
| Not close to artificial learning, as the machine is trained with specific input data to get specific output | Close to artificial learning, as it improves learning from every instance of data processing event |
| Used in solving classification and regression computing problems
|
Used in solving clustering and association computing problems
|
Read more: Exploring Deep Learning Models for Natural Language Processing
Which Machine Learning Technique is Good to Train the Machines?
The choice between using supervised or unsupervised learning depends on your use case, as well as the structure and volume of your data. Supervised learning is preferable for recurring, well-defined problems or for predicting new ones. On the other hand, if you are dealing with big data and want to identify different data sets and patterns within it, unsupervised learning is unparalleled.

As a seasoned professional with over a decade of experience in technology and business magazine publication, I’ve had a front-row seat to witness the astounding pace at which the industry has evolved, often outstripping even Moore’s Law. My passion lies in crafting engaging technology articles that invite readers to immerse themselves in the dynamic and ever-changing world of technology. With each piece, I strive to create a window into this world, offering a glimpse of the amazing events and breakthroughs that continue to shape our future.



